|
Lifeng Huang, Tian Su, Chengying Gao, Ning Liu, Qiong Huang*
Intro:
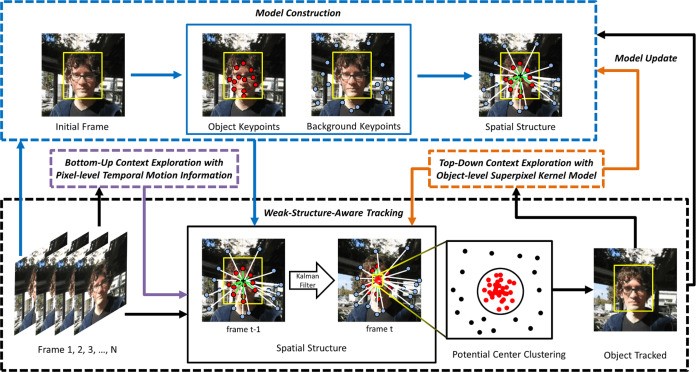
Adversarial attacks poses a significant threat to the security of AI-based systems. To counteract these attacks, adversarial training (AT) and ensemble learning (EL) have emerged as widely adopted methods for enhancing model robustness. However, a counter-intuitive phenomenon arises where the simple combination of these approaches may potentially compromising adversarial robustness of ensemble models. In this paper, we propose a novel method called Alignment and Unlearning for Training Ensembles (AUTE), aiming to effectively integrate AT and EL to maximize their benefits. Specifically, AUTE incorporates two key components. Firstly, AUTE divides the ensemble into a big peer model and a single member in a loop manner, aligning their outputs for boosting robustness of each member.Secondly, AUTE introduces the concept of unlearning, actively forgetting specific data with over-confident properties to preserve model capacity to learn more robust features. Extensive experiments across various datasets and networks illustrate that AUTE achieves superior performance compared to baselines. For instance, a 5-member AUTE with ResNet-20 networks outperforms state-of-the-art method by 2.1\% and 3.2\% in classifying clean and adversarial data. Additionally, AUTE can easily extend to non-adversarial training paradigm, surpassing current standard ensemble learning methods by a large margin. The source code is publicly available at https://github.com/mesunhlf/AUTE.
AAAI, 2025 (中科院 1区/CCF-A)
[Paper]
[Code]
|
|
Wenzi Zhuang, Lifeng Huang, Chengying Gao, Ning Liu*
Intro:
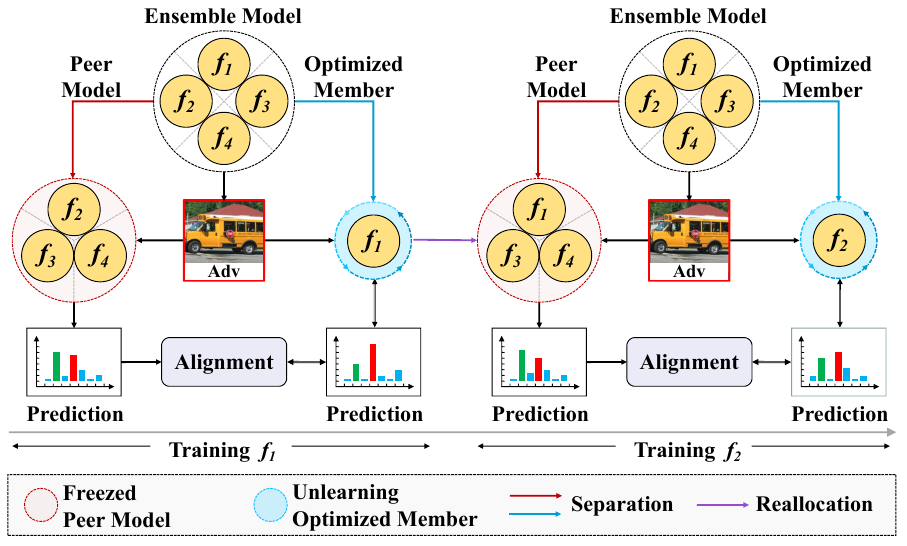
In this work, we revisit the model diversity from the perspective of data and discover that high similarity between training batches decreases feature diversity and weakens ensemble robustness. To this end, we propose LAFED, which reconstructs training sets with diverse features during the optimization, enhancing the overall robustness of an ensemble. For each sub-model, LAFED treats the vulnerability extracted from other sub-models as raw data, which is then combined with round-changed weights with a stochastic manner in the latent space. This results in the formation of new features, remarkably reducing the similarity of learned representations between the sub-models. Furthermore, LAFED enhances feature diversity within the ensemble model by utilizing hierarchical smoothed labels.
Pattern Recognition (PR), 2023 (中科院 1区)
[Paper]
[Code]
|
|
Lifeng Huang, Qiong Huang, Peichao Qiu, Shuxin Wei, Chengying Gao*
Intro:
Recent works show that adversarial attacks threaten the security of deep neural networks (DNNs).
To tackle this issue, ensemble learning methods have been proposed to train multiple sub-models
and improve adversarial resistance without compromising accuracy.
However, these methods often come with high computational costs, including multi-step optimization
to generate high-quality augmentation data and additional network passes to optimize complicated regularization.
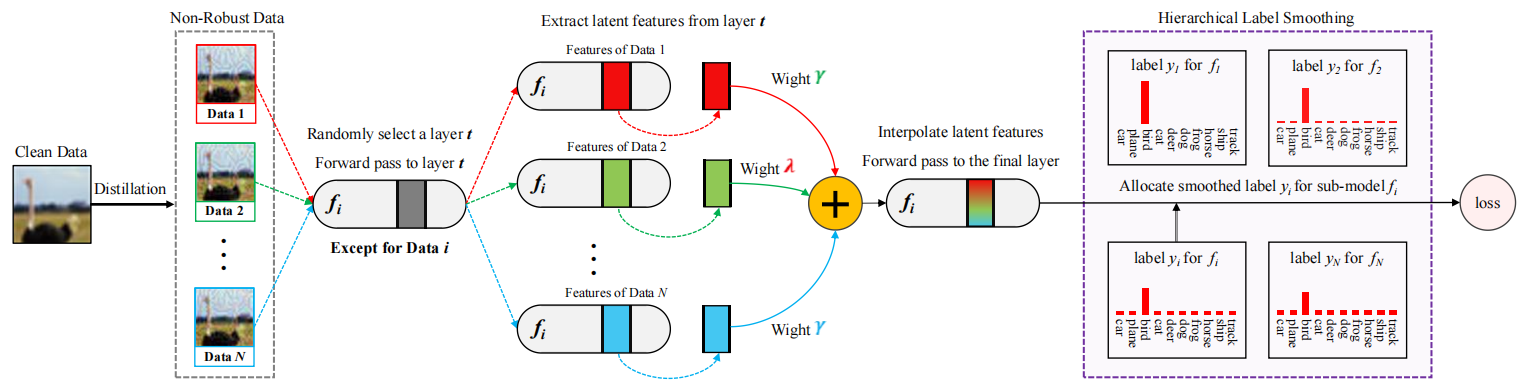
In this paper, we present the FAST ENsemble learning method (FASTEN) to significantly reduce training costs in terms of data and optimization.
Firstly, FASTEN employs a single-step technique to initialize poor augmentation data and recycles optimization knowledge to enhance data quality,
which considerably reduces the data generation budget.
Secondly, FASTEN introduces a low-cost regularizer to increase intra-model similarity and inter-model diversity,
with most of the regularization components computed without network passes, further decreasing training costs.
IEEE Transactions on Information Forensics and Security (TIFS), 2023 (中科院 1区/CCF-A)
[Paper]
[Code]
|
|
Lifeng Huang, Chengying Gao*, Ning Liu
Intro:
Although adversarial examples pose a serious threat to deep neural networks,
most transferable adversarial attacks are ineffective against black-box defense models.
This may lead to the mistaken belief that adversarial examples are not truly threatening.
In this paper, we propose a novel transferable attack that can defeat a wide range of black-box defenses
and highlight their security limitations. We identify two intrinsic reasons why current attacks may fail,
namely data-dependency and network-overfitting. They provide a different perspective on improving the transferability of attacks.
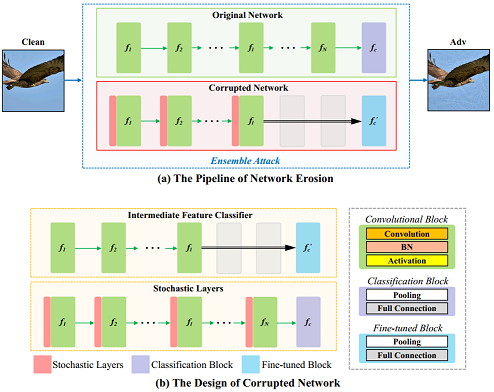
To mitigate the data-dependency effect, we propose the Data Erosion method.
It involves finding special augmentation data that behave similarly in both vanilla models and defenses,
to help attackers fool robustified models with higher chances.
In addition, we introduce the Network Erosion method to overcome the network-overfitting dilemma.
The idea is conceptually simple: it extends a single surrogate model to an ensemble structure with high diversity,
resulting in more transferable adversarial examples.
Two proposed methods can be integrated to further enhance the transferability, referred to as Erosion Attack (EA).
We evaluate the proposed EA under different defenses that empirical results demonstrate the superiority of EA over existing transferable attacks
and reveal the underlying threat to current robust models.
IEEE Transactions on Image Processing (TIP), 2023 (中科院 1区/CCF-A)
[Paper]
[Code]
|
|
Lifeng Huang, Chengying Gao, Ning Liu
Intro:
Adversarial attacks pose a security challenge for deep neural networks, motivating researchers to build various defense methods.
Consequently, the performance of black-box attacks turns down under defense scenarios.
A significant observation is that some feature-level attacks achieve an excellent success rate to fool undefended models,
while their transferability is severely degraded when encountering defenses, which give a false sense of security.
In this paper, we explain one possible reason caused this phenomenon is the domain-overfitting effect,
which degrades the capabilities of feature perturbed images and makes them hardly fool adversarially trained defenses.
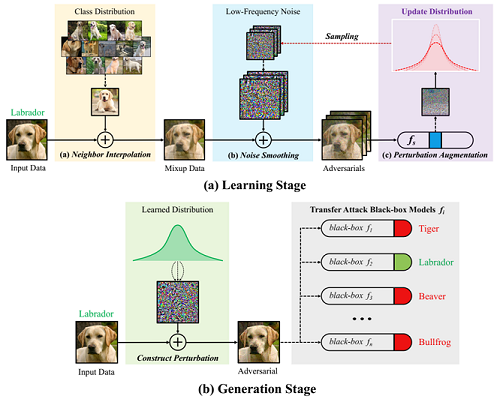
To this end, we study a novel feature-level method, referred to as Decoupled Feature Attack (DEFEAT).
Unlike the current attacks that use a round-robin procedure to estimate gradient estimation and update perturbation,
DEFEAT decouples adversarial example generation from the optimization process.
In the first stage, DEFEAT learns a distribution full of perturbations with high adversarial effects.
And it then iteratively samples the noises from learned distribution to assemble adversarial examples.
On top of that, we can apply transformations of existing methods into the DEFEAT framework to produce more robust perturbations.
We also provide insights into the relationship between transferability and latent features
that helps the community to understand the intrinsic mechanism of adversarial attacks.
Neural Networks, 2022 (中科院 1区/CCF-B)
[Paper]
[Code]
|
|
Lifeng Huang, Shuxin Wei, Chengying Gao, Ning Liu
Intro:
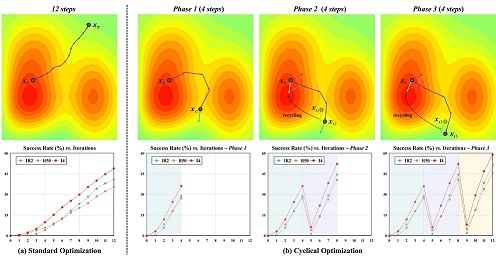
In this paper, we propose Cyclical Adversarial Attack (CA2),
a general and straightforward method to boost the transferability to break defenders.
We first revisit the momentum-based methods from the perspective of optimization and find that they usually suffer from the transferability saturation dilemma.
To address this, CA2 performs cyclical optimization algorithm to produce adversarial examples.
Unlike the standard momentum policy that accumulates the velocity to continuously update the solution,
we divide the generation process into multiple phases and treat the velocity vectors from the previous phase as proper knowledge to guide a new adversarial attack with larger steps.
Moreover, CA2 applies a novel and compatible augmentation algorithm at every optimization in a loop manner for enhancing the black-box transferability further, referred to as cyclical augmentation.
Pattern Recognition (PR), 2022 (中科院 1区/CCF-B)
[Paper]
[Code]
|
|
Lifeng Huang, Wenzi Zhuang, Chengying Gao, Ning Liu
Intro:
Recently, adversarial attacks pose a challenge for the security of Deep Neural Networks,
which motivates researchers to establish various defense methods.
However, do current defenses achieve real security enough?
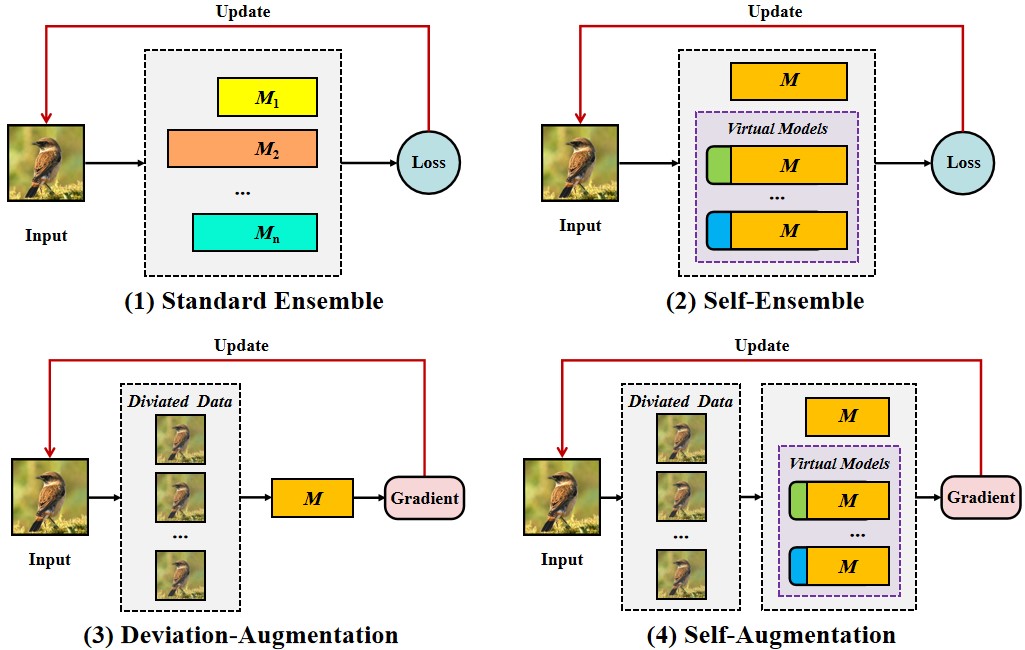
To answer the question, we propose self-augmentation method (SA)
for circumventing defenders to transferable adversarial examples.
Concretely, self-augmentation includes two strategies:
(1) self-ensemble, which applies additional convolution layers to an existing model
to build diverse virtual models that be fused for achieving an ensemble-model effect
and preventing overfitting; and
(2) deviation-augmentation, which based on the observation of defense models
that the input data is surrounded by highly curved loss surfaces,
thus inspiring us to apply deviation vectors to input data for escaping from their vicinity space.
Notably, we can naturally combine self-augmentation with existing methods
to establish more transferable adversarial attacks.
Extensive experiments conducted on four vanilla models and ten defenses suggest the superiority of our method
compared with the state-of-the-art transferable attacks.
International Conference on Multimedia & Expo (ICME, 2021) (*oral) (CCF-B)
[Paper]
[Code]
|
|
Lifeng Huang, Chengying Gao, Yuyin Zhou, Changqing Zou, Cihang Xie, Alan Yuille, Ning Liu
Intro:
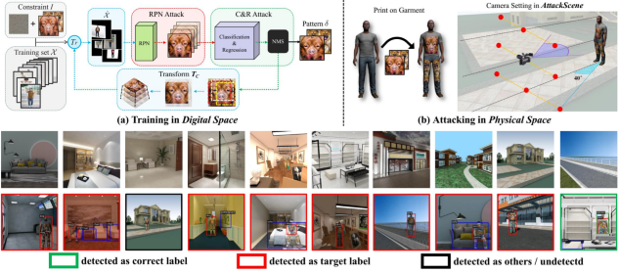
In this paper, we study physical adversarial attacks on object detectors in the wild.
Previous works on this matter mostly craft instance-dependent perturbations
only for rigid and planar objects.
To this end, we propose to learn an adversarial pattern to effectively
attack all instances belonging to the same object category (e.g., person, car),
referred to as Universal Physical Camouflage Attack (UPC).
Concretely, UPC crafts camouflage by jointly fooling the region proposal network,
as well as misleading the classifier and the regressor to output errors.
In order to make UPC effective for articulated non-rigid or non-planar objects,
we introduce a set of transformations for the generated camouflage patterns to
mimic their deformable properties.
We additionally impose optimization constraint to make generated patterns look
natural to human observers. To fairly evaluate the effectiveness of different
physical-world attacks on object detectors, we present the first standardized
virtual database, AttackScenes, which simulates the real 3D world in a controllable
and reproducible environment. Extensive experiments suggest the superiority of
our proposed UPC compared with existing physical adversarial attackers not only
in virtual environments (AttackScenes), but also in real-world physical environments.
Computer Vision and Pattern Recognition (CVPR, 2020) (CCF-A)
[Paper]
[Project Page]
|
|
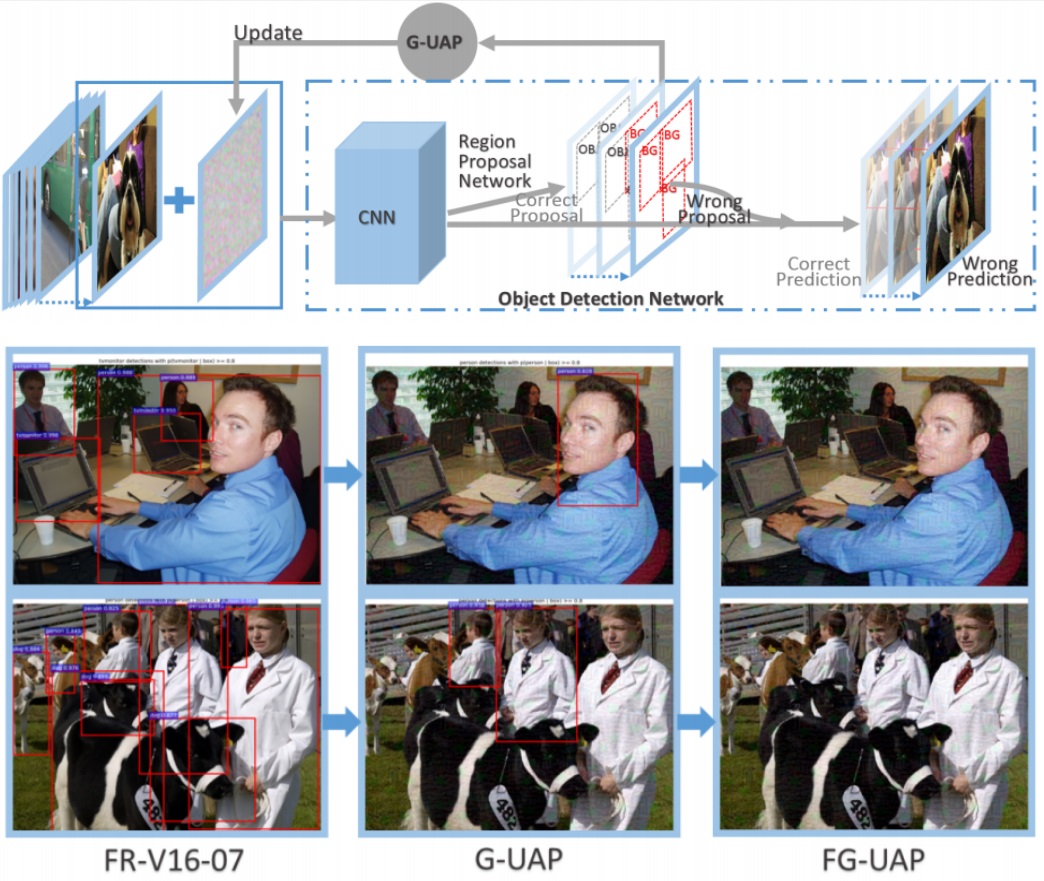
Xing wu, Lifeng Huang, Chengying Gao*
Intro:
Our paper proposed the G-UAP which is the first work to craft universal
adversarial perturbations to fool the RPN-based detectors. G-UAP focuses
on misleading the foreground prediction of RPN to background to make detectors
detect nothing.
Asian Conference on Machine Learning (ACML, 2019) (CCF-C)
[Paper]
|